|
I am a first year Ph.D student at BAIR (Berkeley Artificial Intelligence) working with Alane Suhr. Previously, I had wonderful experience working with Mohit Bansal at UNC-NLP, MURGe-Lab and Ziyi Yang at Microsoft. I did my undergrad at UNC Chapel Hill! Email / CV / Google Scholar / Twitter / Github |

|
|
My primary research interests lie in the area of multi-modal learning, natural language processing, and machine learning. |
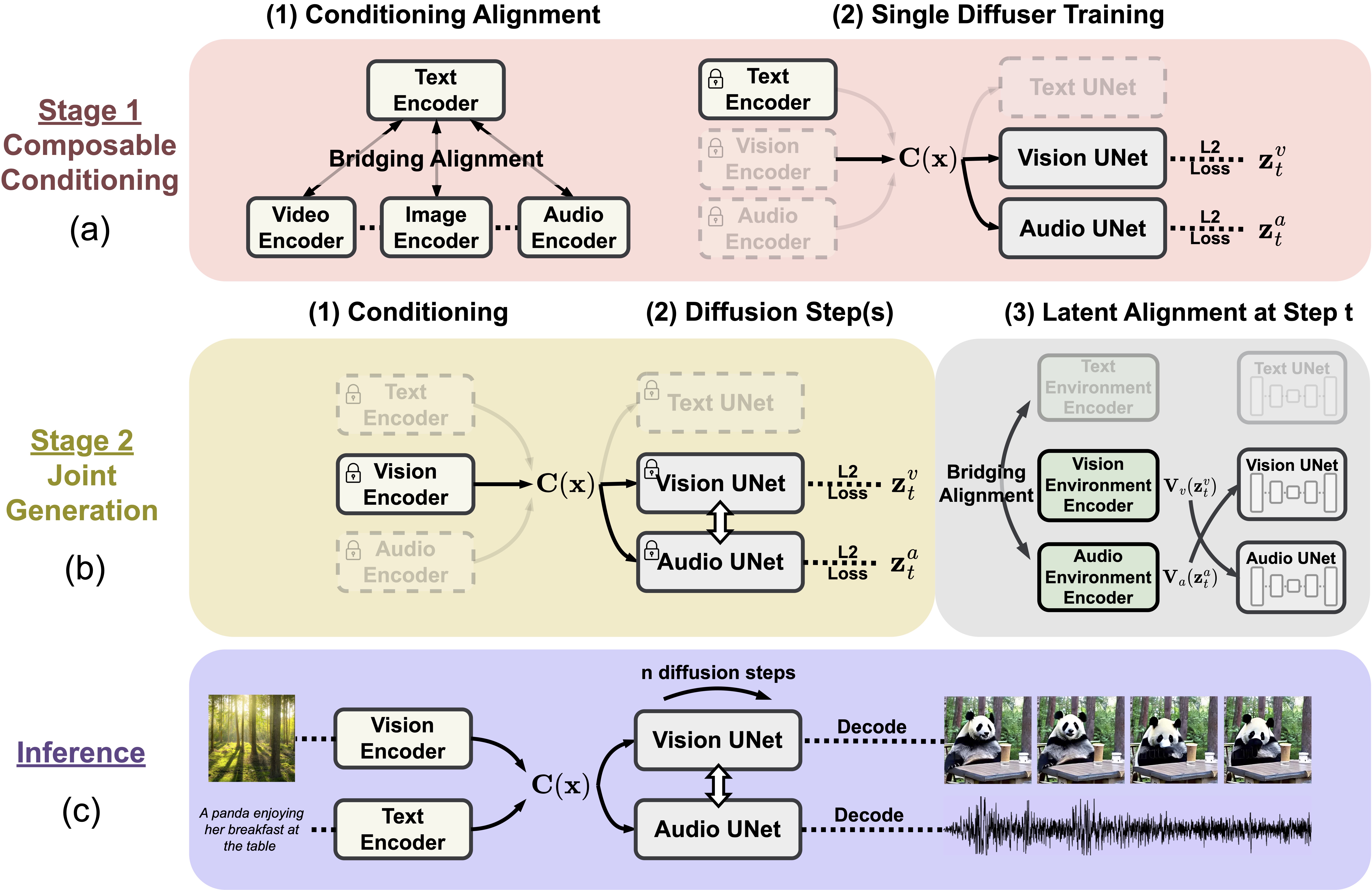
|
Zineng Tang, Ziyi Yang, Yang Liu, Chenguang Zhu, Michael Zeng, Mohit Bansal Arxiv, 2023 Project Page / github / arXiv We built a framework for any to any modality mapping. |
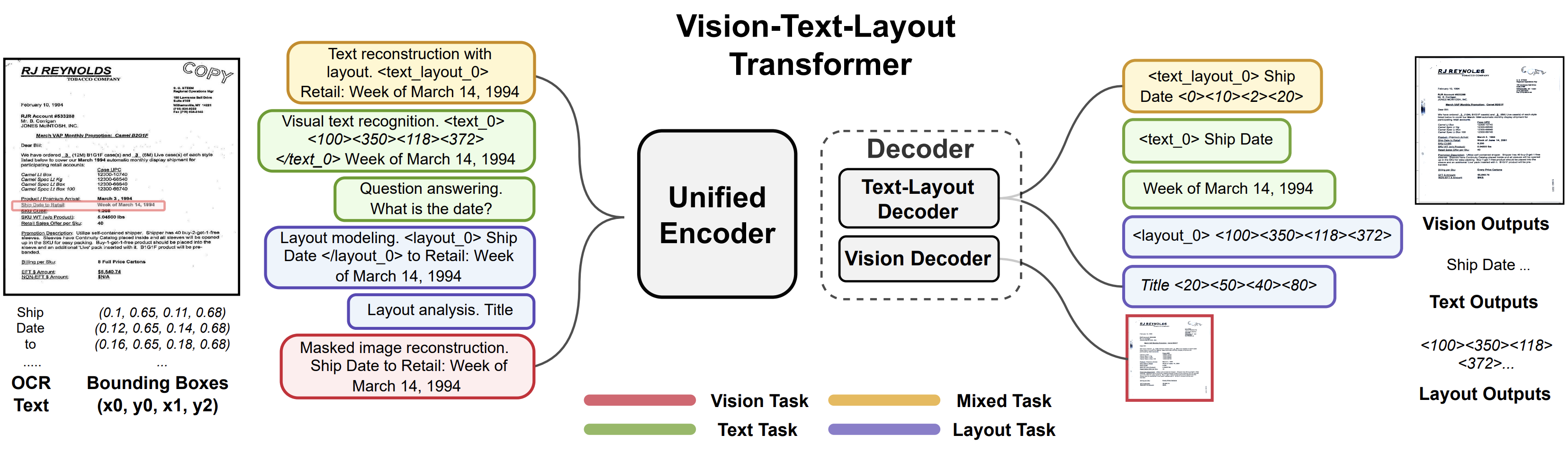
|
Zineng Tang, Ziyi Yang, Guoxin Wang, Yuwei Fang, Yang Liu, Chenguang Zhu, Michael Zeng, Cha Zhang, Mohit Bansal CVPR, 2023 (Highlight; 2.5% acceptance rate) github / arXiv We built a unified framework for document processing. |
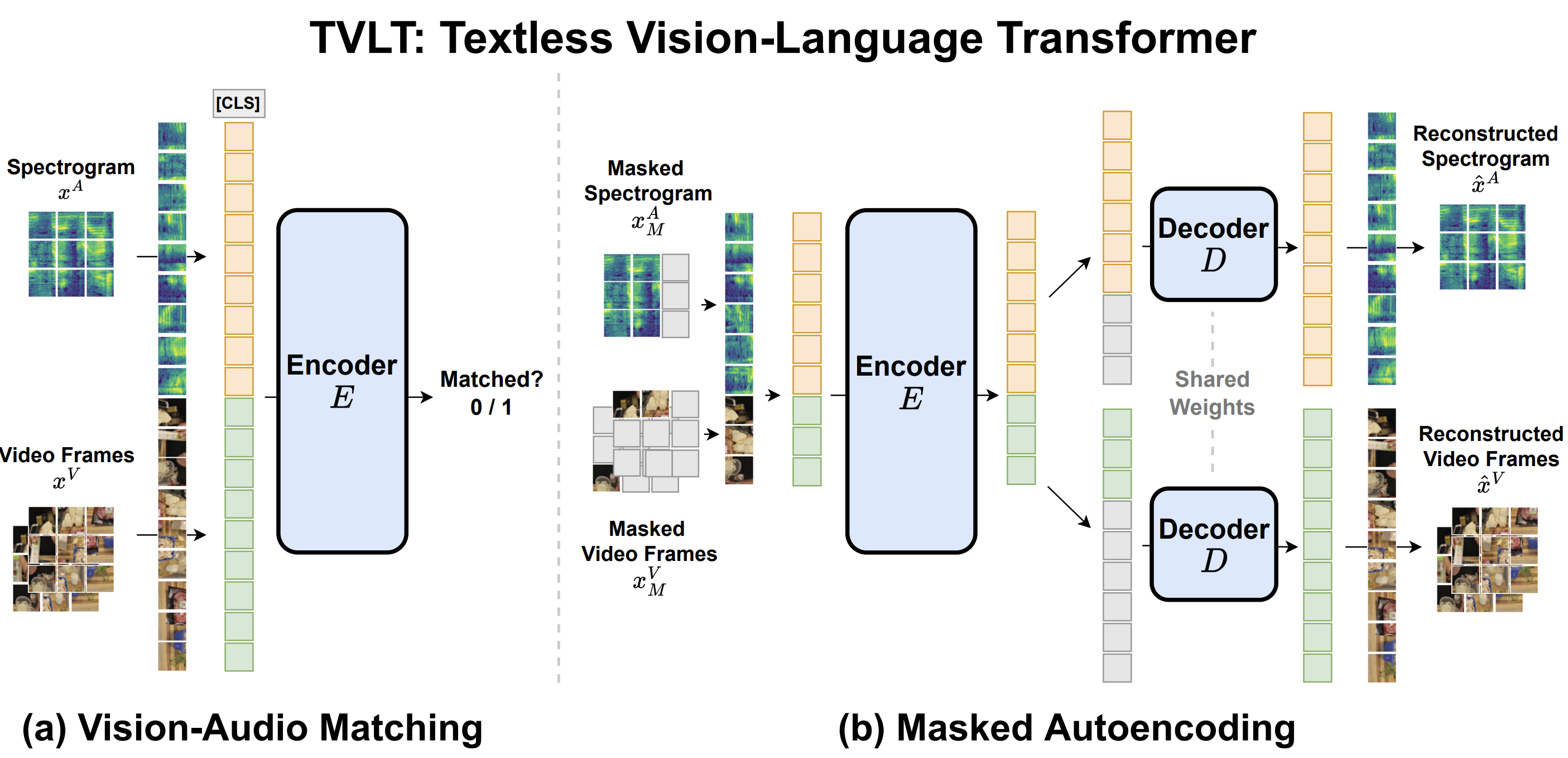
|
Zineng Tang*, Jaemin Cho*, Yixin Nie*, Mohit Bansal NeurIPS, 2022 (Oral; 1.76% acceptance rate) github / arXiv We built a textless vision-language transformer with a minimalist design. |
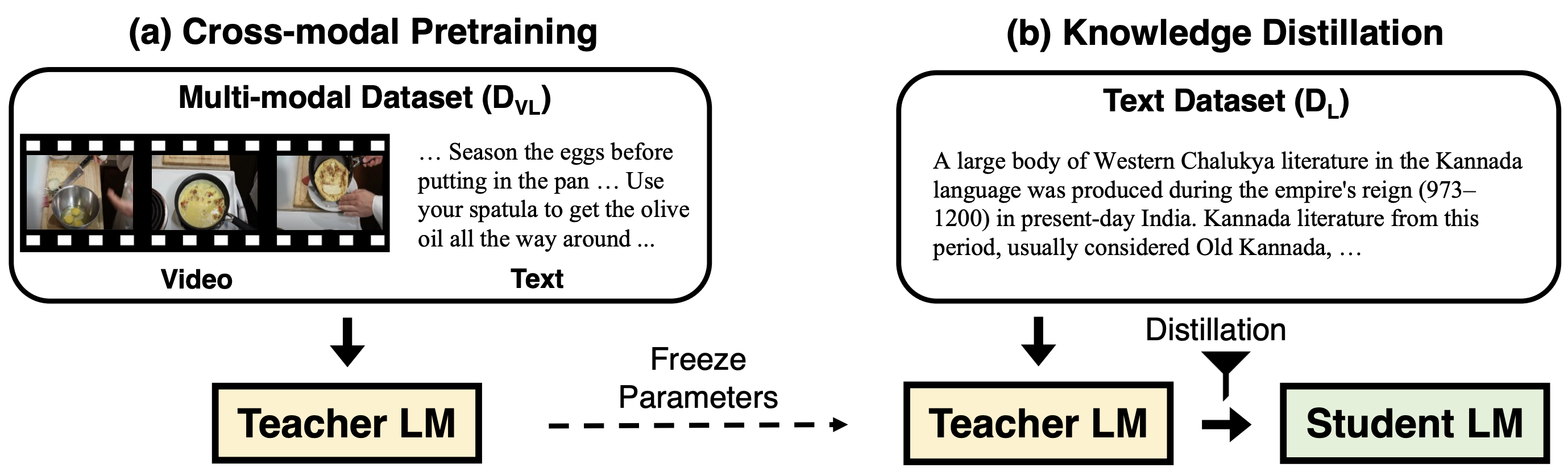
|
Zineng Tang, Jaemin Cho, Hao Tan, Mohit Bansal NeurIPS, 2021 github / arXiv We built a teacher-student transformer for visually grounded language learning. |
|
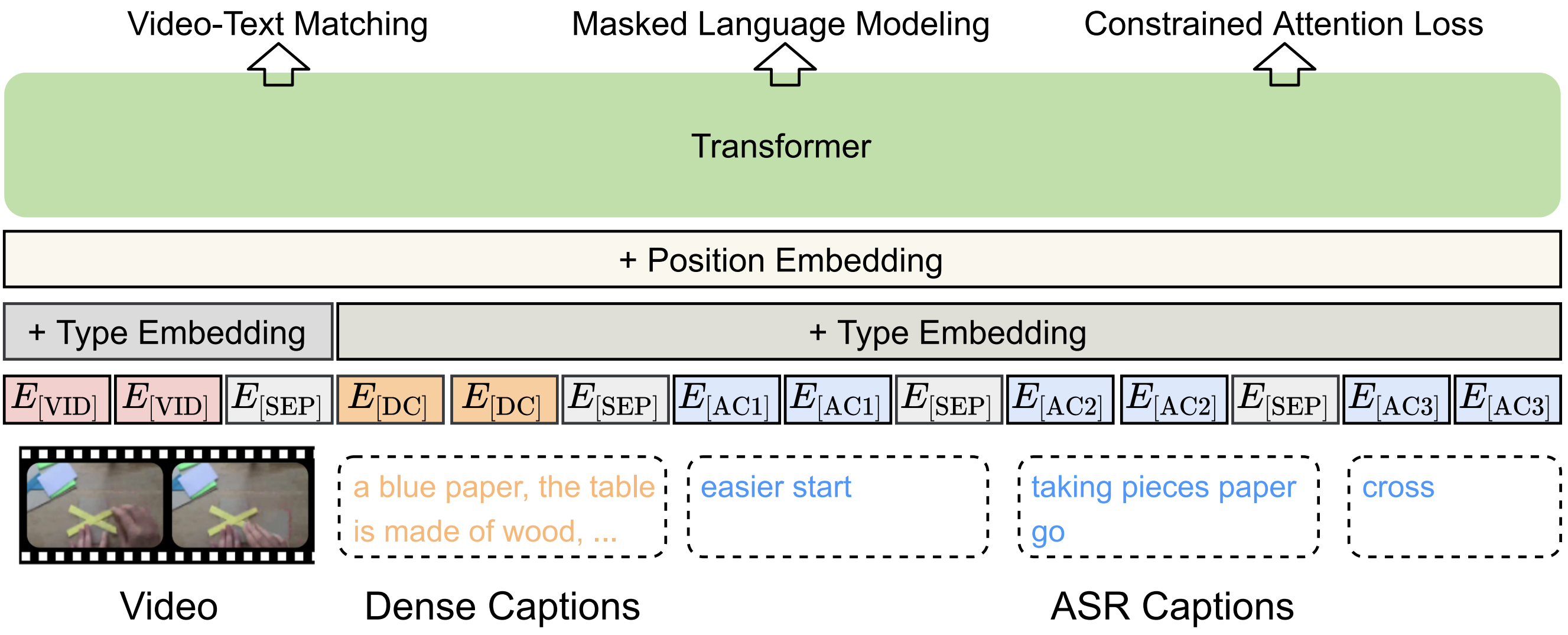
Zineng Tang*, Jie Lei*, Mohit Bansal NAACL, 2021 github / paper We built a video-language transformer that addresses the issues of noisy ASR data by dense captions and entropy minimization. |
|
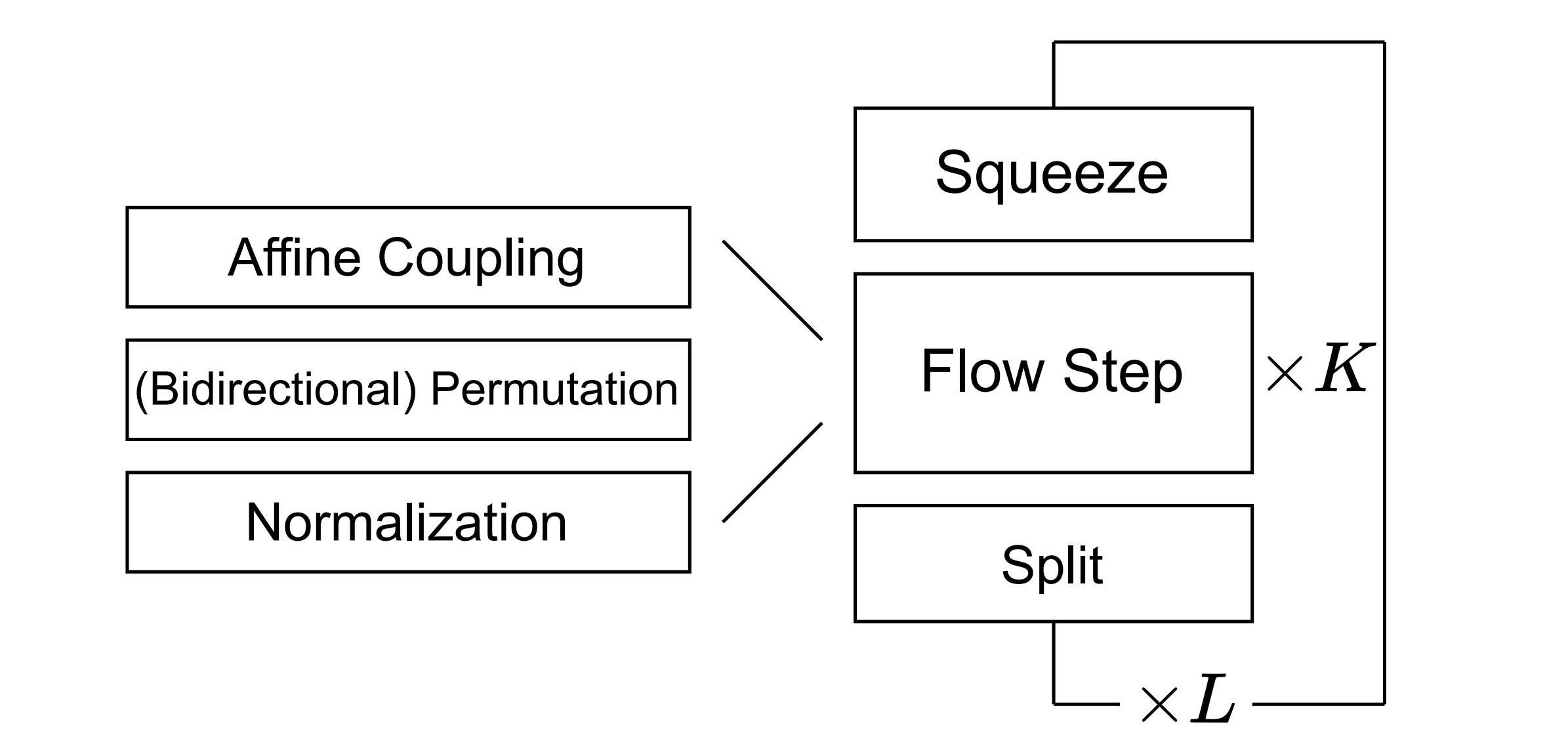
Zineng Tang, Shiyue Zhang, Hyounghun Kim, Mohit Bansal ACL, 2021 github / paper We built a language framework basde on continuous generative flow. |
|
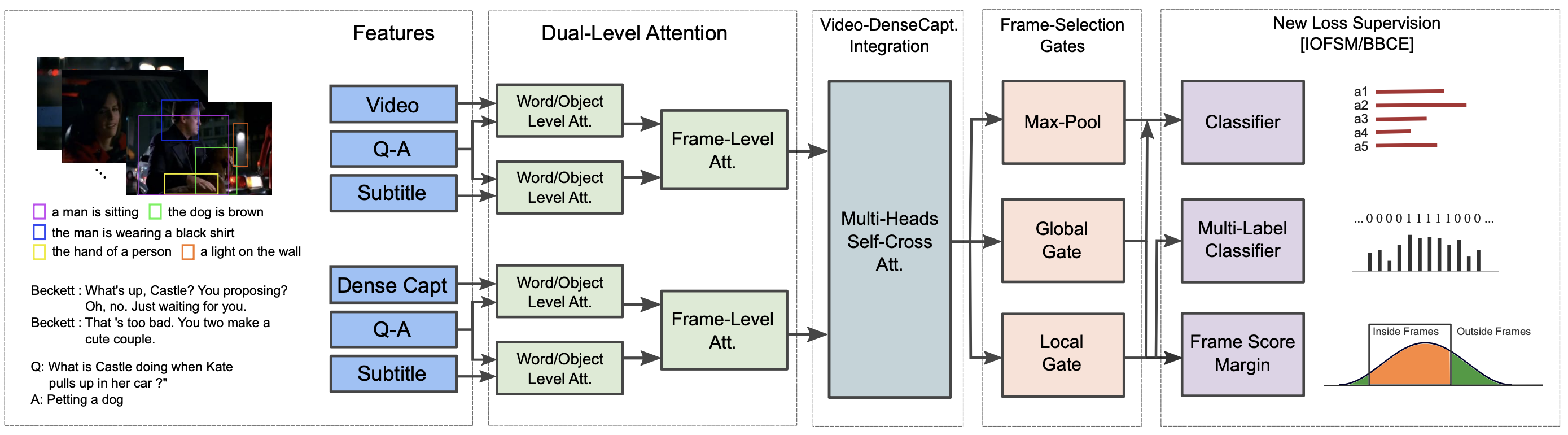
Hyounghun Kim, Zineng Tang, Mohit Bansal ACL, 2020 github / arxiv We built a video QA framework basde on various techniques like dense captions. |
|
|
 |
UNC Chapel Hill, B.S. in Mathematics, 2019 - present |
|
|
|
MURGe-Lab, Undergraduate Research Assistant |
|
 |
Microsoft Azure Cognitive Services Research, Research Intern |
|
|
|
NeurIPS 2022 Scholar Award Awardee, Outstanding Undergraduate Researcher Award 2023. Computing Research Association (CRA) |
|
Website template mainly borrowed from Here |